
Google Research just dropped something that actually matters for climate science: Groundsource. It’s a methodology that uses Gemini to chew through news reports and spit out structured, historical disaster data. The first output is an open-access dataset of 2.6 million urban flash flood events spanning 150+ countries, from 2000 to today.
If you’ve ever tried to train a flood prediction model, you know the pain. Unlike earthquakes, which have decent global sensor coverage, floods are a mess. Satellite data is great but gets blocked by clouds, misses fast-moving events, and only catches the big ones. The Dartmouth Flood Observatory and Global Flood Database are useful but limited. GDACS, the UN/European Commission system, has about 10,000 entries — focused on high-impact disasters.
Ten thousand records sounds like a lot until you realize you need millions to train modern AI models. Flash floods in particular are under-recorded because they’re local and quick. You can’t build reliable global models on that.
Groundsource’s approach is straightforward in concept but brutal to execute manually: scrape news articles, government reports, and local bulletins from around the world, then extract location, date, severity, and other details. The scale is the key — manual extraction is impossible, but Gemini makes it feasible. The pipeline handles language variety, inconsistent formatting, and the noise of real-world reporting.
The result is 2.6 million records, which is orders of magnitude more than existing flood databases. That’s enough data to actually train and validate models that could predict flash floods in urban areas where they cause the most damage.
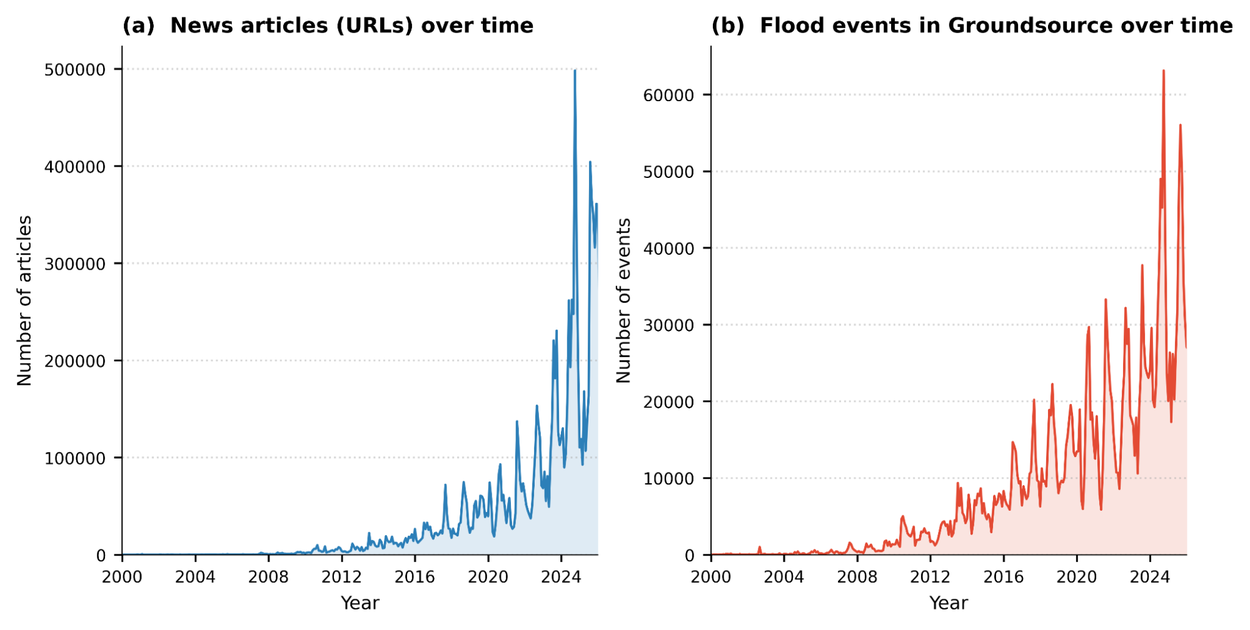
The chart above shows the explosion of digitized news and corresponding flood events captured. The density spike from 2020-2025 is striking — more news, more data, better coverage.
Is it perfect? No. News reports have biases — wealthier areas get more coverage, English-language sources dominate, and sensational events get disproportionate attention. The team acknowledges these limitations. But it’s a massive step forward from the data desert we had before.
The methodology is also potentially reusable for other hazards — wildfires, landslides, maybe even disease outbreaks. If they open-source the pipeline, that could accelerate crisis resilience work globally.
I’m more optimistic about this than most AI-for-good announcements because it solves a concrete, measurable problem: we need historical data to predict future disasters, and we weren’t getting it from traditional sources. Using news as a sensor network is clever, and the scale here is genuinely impressive.
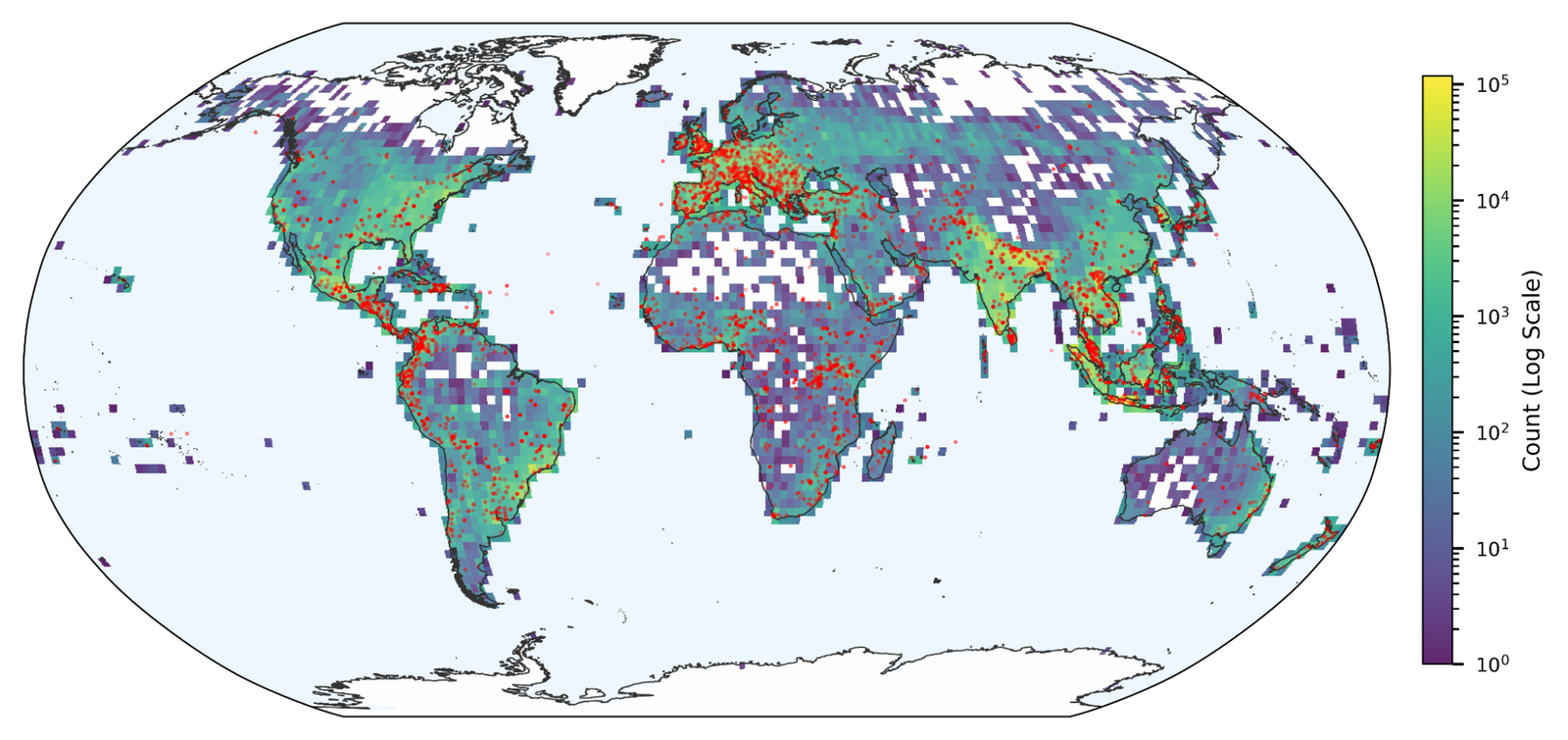
The dataset is open-access, which is the right call. Let’s see what researchers and practitioners do with it.
Comments (0)
Login Log in to comment.
Be the first to comment!